人工智能學家質疑谷歌圍棋AI有科學欺詐表現

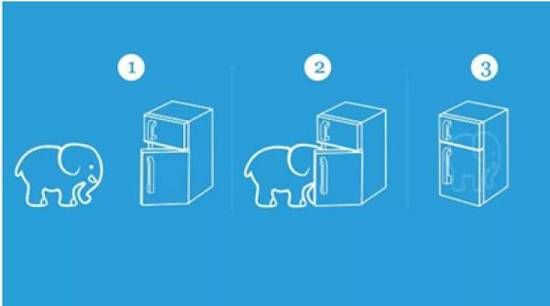
在討論谷歌圍棋AI及其比賽問題之前,我們先看那個著名的笑話“把大象關進冰箱要幾步“,2000年中國春晚,趙本山、宋丹丹的小品《鐘點工》,曾經用到了這個笑話:問“把大象放進冰箱總共分幾步?”答:“三步,第一步把冰箱門打開;第二步把大象放進去,第三步把冰箱門帶上”。
小品中的情景只是一個笑話,但從科研角度看,因爲故意忽視最爲關鍵的第二步,使得這個原本偉大的科學實驗,變成了笑話段子。本文提出谷歌圍棋AI及其比賽有科學欺詐表現,根源也在這裡。
谷歌圍棋AI在Nature上究竟說了什麼
谷歌在Nature發表論文闡述了其圍棋AI程序AlphaGo的運行原理,這個原理描述相對專業,這裡我們也力爭用通俗易懂的語言描述谷歌究竟說了什麼,谷歌圍棋AI程序AlphaGo在下棋過程中主要通過四步完成工作,它們分別是:
第一步快速判斷:用於快速的觀察圍棋的盤面,類似於人觀察盤面獲得的第一反應
第二步深度模仿 :AlphaGo學習近萬盤人類歷史高手的棋局來進行模仿學習,用得到的經驗進行判斷。這個深度模仿能夠根據盤面產生類似人類棋手的走法。
第三步自學成長:AlphaGo不斷與“自己”對戰,下了3000萬盤棋局,總結出經驗作爲棋局中的評估依據。
第四步全局分析:利用第三步學習結果對整個盤面的贏面判斷,實現從全局分析整個棋局。
判斷欺詐的第一個原因,谷歌的把大象關冰箱問題
Nature論文闡述的AlphaGo基本原理,按照人工智能專家的評價:”其基本原理並沒有新東西“,但核心價值是學習了近萬盤人類歷史高手的棋局,和自我對戰下的3000萬盤棋局總結的經驗。
請注意,這個關鍵內容,也就是AlphaGo到底終結出什麼圍棋規律,或者其神經網絡的權重值是什麼,谷歌並沒有發表出來。也就是谷歌在”大象關進冰箱要幾步“問題上,說出瞭如何打開圍棋戰勝人類的冰箱大門,和如何關上圍棋戰勝人類的冰箱大門,但唯獨在第二步 圍棋如何戰勝人類的方法塞進冰箱,同樣做了隱藏。
我們知道,圍棋之所以很難被人工智能攻破,戰勝人類高手,就是其可能的組合數異常龐大。至於多麼異常,2016年1月普林斯頓的研究人員給出了最新研究結果:對於一個19x19的圍棋棋盤而言,一共有361個位置,而每個位置可以單獨放置黑棋、白棋或者留空,理論上所有的可能組合是3^361種。但根據圍棋規則,不是所有位置都可合法落子,例如在圍棋術語中沒有氣的位置就不能落子。那麼排除掉這些不合法的棋局後總共還剩多少種呢?
普林斯頓的研究人員給出的19x19格圍棋的精確合法棋局數:208168199381979984699478633344862770286522453884530548425639456820927419612738015378525648451698519643907259916015628128546089888314427129715319317557736620397247064840935
我們給它多分幾行:
2081681993819799846
9947863334486277028
6522453884530548425
6394568209274196127
3801537852564845169
8519643907259916015
6281285460898883144
2712971531931755773
6620397247064840935
不用數了,一共171位數! 這個數字比我們地球所有的沙粒數量還要多!比人類已知宇宙的所有星球數量還要多!對比一下,谷歌學習的近萬盤人類棋局是5位數,谷歌自行對戰的3000萬盤是8位數。而圍棋所有可能的棋局盤數是171位數。如果規避還有可能的重複變化,我們把大頭去掉,那也有70位數的棋局變化。
第一也就是說谷歌以幼兒園規模的知識量,就要獲得諾貝爾獎級的知識規律,這違背了科學發展規律和常識
第二,如果谷歌通過學習和自行對戰學到了超出尋常的規律,或者其神經網絡權重值達到新的高度狀態。但谷歌不願意公開這個最重要最關鍵的內容,其他研究者就無法真正瞭解谷歌圍棋的真實水平。在這種情況下,匆忙舉辦獲得巨大商業利益,沒有第三方真正監督,無法洗脫作弊嫌疑的世界冠軍比賽。受到科學欺詐指控也屬必然。
判斷欺詐的第二個原因,密室實驗與棋手放水
從科學實驗的嚴謹性說,谷歌在論文中闡述的實驗方法,表現不及格甚至惡劣,我們知道在物理,化學,生物,計算機等領域,進行實驗時,要求實驗對象必須達到一定數量,並進行多次獨立實驗。才能相對確保結果的穩定性和可靠性。譬如一個受到污染的試管,無論我們重複多少次實驗,其結果也一定是不可靠的。
谷歌在這篇論文中 對其他圍棋程序選取了衆多測試對象,並進行了495次實驗,但對人類測試者,卻只選取了一位曾經獲得歐洲圍棋冠軍的棋手,並簽署嚴格的保密協議,原本可以很容易邀請更多選手,但卻沒有按照科學規範進行多次實驗。先不談谷歌和棋手之間有無利益交易,就這一點,谷歌在Nature發表的論文從實驗角度是不合格的。
更重要的問題出在與谷歌對戰的歐洲圍棋冠軍樊麾身上,在對戰棋譜公佈後的二個月裡,大量職業圍棋高手含蓄或公開指出樊麾水平發揮失常,或不求進取,或就是放水。
多次戰勝李世石,當前世界最優秀的圍棋選手柯潔評價道:“他可能也是好久不下棋了,實力表現非常糟糕”。前北京市高校圍棋冠軍王爍在財新發布的文章中評價道:“這五局棋下得反而是很平庸。樊麾抵抗不足,五盤棋沒有什麼激烈的戰鬥,開局、定式、佔大場、小規模接觸戰,收官,對抗度很差。”
雖然歐洲圍棋冠軍樊麾多次辯解“我發揮失常,當時崩潰了“,但更多棋友評價歐洲圍棋冠軍樊麾,“發揮有技術變形”,“樊麾的表現只有業4水準,關鍵地方明顯放水”,“很明顯樊麾是谷歌公司的託,全是50年前的招法極其保守,不輸纔怪”,“對於谷歌,沒有什麼謊言是不能用1千萬美金解決的”。
除此之外,谷歌也沒有向Facebook那樣把圍棋程序放到互聯網上,光明磊落的接受大衆的考驗,作爲與谷歌AlphaGo原理相同facebook圍棋程序DarkForest,目前水平相當於業餘5段,與職業選手依然有巨大的差距。
同時谷歌的論文結論也存在不可重複問題,Facebook圍棋項目負責人田淵棟在評價谷歌圍棋AI最爲關鍵的快速走子策略時講到”對此AlphaGo只提供了局部特徵的數目,而沒有說明特徵的具體細節。我最近也實驗了他們的辦法,達到了25.1%的準確率和4-5微秒的走子速度,然而全系統整合下來並沒有復現他們的水平。我感覺上24.2%並不能完全概括他們快速走子的棋力,因爲只要走錯關鍵的一步,局面判斷就完全錯誤了“。
從上述情況看,谷歌在進行圍棋實驗的過程中,刻意違反科學實驗規範,存在採用密室孤立實驗,這些問題在3月9日與韓國選手李世石的比賽中沒有消除。人們常說,互聯網上,你不知道你的對面坐的是人還是條狗。同樣對於谷歌圍棋比賽,我們完全可以質疑,與李世石對弈的究竟是程序還是人?如何保證李世石沒有被利益收買?
判斷欺詐的第三個原因,過度追求市場影響
谷歌選擇歐洲圍棋冠軍和前圍棋冠軍李世石進行世界轟動的比賽,而且沒有嚴格的第三方監督,排除作弊的可能,表明谷歌並不是追求科學的嚴謹和榮譽,而是在追求品牌和影響力最大化,從而獲得巨大的經濟利益。
事實也證明這一點,2016年1月28日曝出了谷歌人工智能圍棋擊敗歐洲冠軍的消息,隨後是谷歌拿出100萬美元作爲獎金挑戰李世石。當日谷歌股價大幅上漲,漲幅4.42%,換算成市值漲了200億美元。從宣傳效果是看,谷歌這次的“廣告”做非常巧妙。2016年2月26日彭博社報道,谷歌旗下設計圍棋AI的公司DeepMind正推進自身醫療技術發展,因爲其在圍棋領域的影響,已經獲得不菲的訂單。
西方諺語說”一個動物,如果它走起來像鴨子 叫起來像鴨子 它就是鴨子“,同樣,對於谷歌圍棋Ai及其比賽,如果它迴避公開如何從3000萬盤(8位數)棋局獲得171位天文數字棋局的規律或神經網絡權重值,迴避不願大範圍邀請棋手參與實驗,迴避收買選手嫌疑,迴避不在互聯網上公開對戰接受監督,那麼谷歌的圍棋比賽可以看作一場精心策劃的科學騙局或有欺詐嫌疑。
商業中有一種做法叫產品期貨,消費者購買商品後,要等到半年或一年後才能拿到,那時技術,原料成本大幅下降,商家因此獲得利潤。同樣,谷歌的圍棋程序應該獲得一定進展,但遠沒有到達能夠挑戰職業選手或九段高手的地步,谷歌通過市場和技術手段,拔高其圍棋水平。故意迴避公開監督或公開大範圍對戰。等待未來水平繼續提升後,可能會進行公開,這種做法也可以稱作 ”技術期貨路徑。
谷歌可以消除欺詐指控的嫌疑,不是與李世石下棋,而是:
1.完整公佈或開源其利用3000萬盤棋局和學習人類棋譜總結的規律,或公開其神經網絡權重值參數,讓其他實驗者可以重複谷歌的實驗結果,還原谷歌對戰成績。
2.將谷歌圍棋AI程序AlphaGo放在互聯網上,接受百人,千人的同時對戰。並檢測對戰結果,消除作弊嫌疑。
這兩條谷歌能做出任意一條,都可以看作是消除欺詐指控的強有力證據,但在未來一年或更長時間裡,谷歌沒有任何動作,那麼谷歌將持續揹負有科學欺詐嫌疑,利用科學炒作獲得巨大經濟利益的指控。
作者介紹:劉鋒,計算機博士,互聯網進化論作者,人工智能學家主編。本文來源人工智能學家,人工智能學家是權威的前沿科技媒體和研究機構,2016年2月成立人工智能與互聯網進化實驗室(AIE Lab),重點研究互聯網,人工智能,腦科學,虛擬現實,機器人,移動互聯網等領域的未來發展趨勢和重大科學問題。
相關資訊
- ▣ 谷歌兩位AI科學家據悉計劃離職並組建人工智能初創公司
 贏了圍棋後…谷歌人工智慧要學爐石戰記與魔法風雲會
贏了圍棋後…谷歌人工智慧要學爐石戰記與魔法風雲會- ▣ 警惕!蘋果、谷歌、三星智能手錶錶帶藏身有毒化學物質
- ▣ 谷歌新人工智能工具,如何變革學生學習?
- ▣ 谷歌學術能挺過人工智能革命嗎?
- ▣ 人工智能將有能力進行科學發現
- ▣ 谷歌學術現涉人工智能研究論文,刪之或更糟
- ▣ 科學家憑人工智能破解蛋白質密碼獲諾獎
- ▣ 地球也有暗物質?科學家發現疑似暗物質粒子,引起學界轟動
- ▣ 人工智能(AI)工程學士學位 BEng in Artificial Intelligence
 AI科技再進化 南大團隊發表用腦波下圍棋創新學習技術
AI科技再進化 南大團隊發表用腦波下圍棋創新學習技術- ▣ 麻省理工學院研究團隊:部分人工智能已學會欺騙人類
- ▣ 科學家藉助AI技術發現病毒“暗物質”
 科學智能又一重要成果:中澳科學家用AI發現超過16萬種新病毒
科學智能又一重要成果:中澳科學家用AI發現超過16萬種新病毒- ▣ 谷歌發佈Gemini 2.0 AI 大舉押注人工智能代理
- ▣ AI For Science熱潮下,人工智能如何顛覆科學研究?
- ▣ 谷歌地圖藉助人工智能,解答新餐廳疑問
- ▣ AI科學家周志華升任南京大學副校長;蘋果:AI功能將成換手機新理由;谷歌推出Chrome AI功能|AI daily早新聞
- ▣ 30秒|天府人工智能大會開幕 人工智能領域專家學者企業家共話AI
- ▣ 科學家利用人工智能加速葡萄育種
- ▣ 谷歌、微軟等14家科技公司成立“安全人工智能聯盟”
- ▣ 谷歌人工智能測試得分達到國際數學奧賽銀牌水平
- ▣ 爲人工智能奠基的科學家勇奪諾貝爾物理學獎
 中國科學家運用人工智能算法發現大量全新RNA病毒
中國科學家運用人工智能算法發現大量全新RNA病毒- ▣ 招聘腦科學、心理學、AI等科研人員:深圳理工大學-“智能與行爲交叉研究中心”
- ▣ 心理學 | 人工智能視域的質性心理學研究
- ▣ 谷歌 Project Astra 如何讓人工智能助手有“眼”
- ▣ 谷歌等科技巨頭推出安全人工智能聯盟
- ▣ 谷歌 DeepMind 科學家憑 AlphaFold 摘獲諾獎